As the landscape of data visualization evolves, the ability to adapt and respond to real-time data becomes increasingly important. Adaptive Information Visualization (InfoVis) systems must integrate seamlessly with real-time data streams to remain effective and impactful. This is where a message broker architecture comes into play, acting as the backbone for adaptive visualizations.
Message Broker Architecture
A message broker architecture is essential for managing and distributing real-time data flows between different components, making it especially crucial for adaptive visualizations where data needs to be processed and presented in real-time.
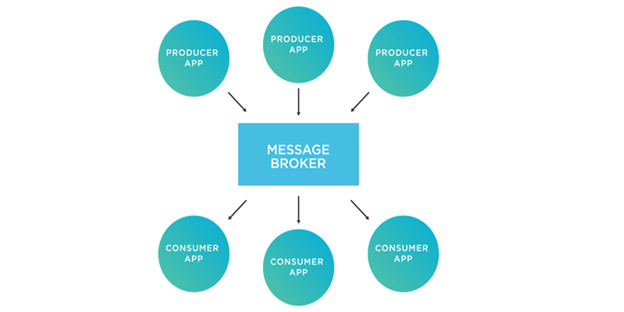
Key Components
Producers (Senders): These are the applications or services that generate messages and send them to the message broker.
Message Broker: A central component that manages the routing and delivery of messages. It supports various protocols (e.g., AMQP, MQTT) and data formats. Its key functions are:
- Message Routing: Direct messages to the correct destination(s) based on rules, topics, or queues.
- Queuing: Temporarily stores messages if consumers are unavailable.
- Transformation: Modify messages (e.g., format changes) before delivery if needed.
- Filtering: Ensure only relevant messages reach the target consumers.
Consumers (Receivers): These applications retrieve messages from the broker and process them asynchronously, which means they don’t need to wait for the producers to send messages.
Communication Patterns: Categorized according to:
- Point-to-Point: Messages are delivered to one consumer (e.g., using queues).
- Publish/Subscribe: Messages are broadcast to multiple consumers subscribed to a specific topic.
Advantages of Apache Kafka in SYMBIOTIK
In SYMBIOTIK, we leverage the power of Apache Kafka to achieve the desired adaptability, ensuring that our visualizations interact seamlessly with the adaptation framework that reflects the cognitive load of the end-user.
Apache Kafka is a distributed streaming platform that excels in handling real-time data feeds. Some of the key advantages of using Kafka in the SYMBIOTIK project include:
- High Throughput: Kafka can handle thousands of messages per second, making it ideal for high-velocity data environments.
- Low Latency: With latency as low as a few milliseconds, Kafka ensures that data is transmitted almost instantaneously, which is critical for real-time visualizations.
- Scalability: Kafka’s distributed architecture allows it to scale out easily by adding more nodes, without incurring downtime.
- Fault Tolerance: Kafka is designed to be fault-tolerant, with built-in mechanisms for data replication and recovery, ensuring that data is never lost.
- Durability: Data in Kafka is persisted on disk, making it durable and reliable.
- Flexibility: Kafka supports a variety of use cases, from real-time analytics to data integration, making it a versatile tool for adaptive visualizations.
In SYMBIOTIK, Kafka serves as the central message broker, facilitating the seamless exchange of data between the involved components of our adaptation framework, and facilitates the dynamic adaptation based on real-time data, ensuring the seamless interaction between the end-users and the visualization system.
In conclusion, the integration of a message broker architecture like Apache Kafka is key to the success of adaptive visualization systems like SYMBIOTIK. It ensures real-time, scalable, and reliable data transmission, enabling dynamic, responsive visualizations that provide a seamless experience for end-users.