To better understand the potential of cognitive data in improving machine learning models, specifically Large Language Models (LLMs), we propose GazeReward, an innovative framework for aligning LLMs with human preferences by incorporating eye-tracking (ET) data into reward modeling.
LLMs like GPT-4 [1], Llama 3 [2], and others have revolutionized Natural Language Processing (NLP), excelling in diverse tasks but often requiring fine-tuning to meet human expectations. A common approach to achieving human alignment involves leveraging explicit feedback as preference information. Traditional approaches like Reinforcement Learning from Human Feedback (RLHF) [3] have been widely used but they face challenges such as scalability, inconsistent human annotations, and high costs [4]. In addition, obtaining high-quality feedback from human annotators, usually provided after examining a model response, suffers from several caveats. For instance, low inter-annotator agreement can result in inconsistent evaluations of the same model output due to varying interpretations, domain expertise, or biases [5].
Incorporating ET data into NLP tasks has proven valuable, as demonstrated by numerous works [6–14]. Recently, Kiegeland et al. [11] proposed the integration of ET in controlled sentiment generation to create a dataset that can be used in human alignment methods. Our work explores leveraging ET data, a form of implicit feedback that reflects cognitive and perceptual processes during reading and language comprehension, to better model preference modeling. The core idea of GazeReward is to use ET features to enhance the Reward Model (RM), which is central to human alignment techniques.
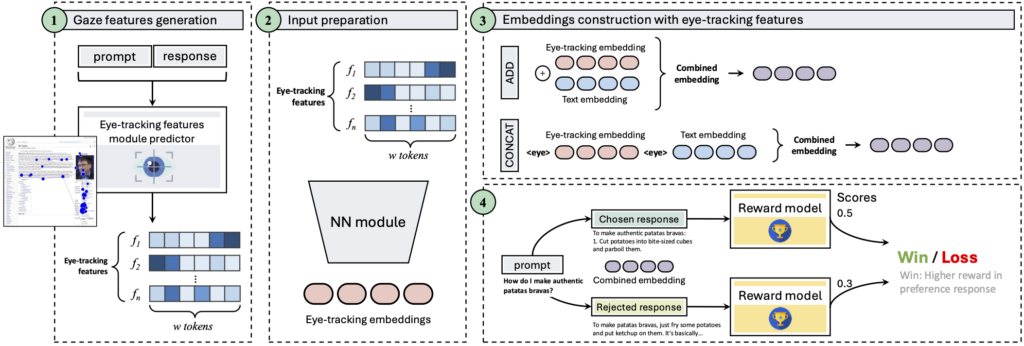
Eye-tracking captures oculomotor behavior—fixations, saccades, and reading patterns—that correlate with attention and information processing. Unlike explicit feedback, ET data is unbiased, temporally precise, and offers rich insights into user preferences [15].
To integrate ET signals, we employed state-of-the-art ET prediction models to generate synthetic gaze features from text prompts and responses. These features were combined with text embeddings using two methods: GazeConcat, which concatenates embeddings, and GazeAdd, which adds them element-wise. We conducted experiments using two datasets: OASST1 and HelpSteer2. These datasets include human-annotated preference pairs, where one response is preferred over another. The RM was fine-tuned using open-source LLMs such as Llama 3 and Mistral, with and without ET features. ET prediction models provided features like first fixation duration (FFD) and total reading time (TRT), which were integrated into the RM via a specially designed feature projector. Performance was measured by the RM’s accuracy in predicting human preferences, using both standard datasets and the RewardBench benchmark.
The results demonstrate that incorporating ET features significantly improves RM accuracy, with gains exceeding 20 percent points in some cases. Future work could involve collecting task-specific ET data and extending the framework to other languages and larger models. Additionally, exploring alternative integration methods, such as modifying attention masks, could further enhance performance.
GazeReward represents a significant step forward in aligning modern AI systems with human values by integrating cognitive data into reward modeling. This work not only improves the performance of existing models but also opens new avenues for research in multimodal AI alignment. By harnessing the power of gaze, we can make AI more aligned to human needs and expectations. Check the paper for more details!
References
- OpenAI. GPT-4 Technical Report, March 2023. http://arxiv.org/abs/2303.08774
- Dubey, A., Jauhri, A., et al. The Llama 3 Herd of Models, August 2024. http://arxiv.org/abs/2407.21783
- Ouyang, L., Wu, J., et al. Training language models to follow instructions with human feedback, March 2022. http://arxiv.org/abs/2203.02155
- Casper, S., Davies, X., et al. Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback, July 2023. http://arxiv.org/abs/2307.15217
- Amodei, D., Olah, C., et al. Concrete Problems in AI Safety, July 2016. http://arxiv.org/abs/1606.06565
- Huang, X., Wan, J., et al. Longer Fixations, More Computation: Gaze-Guided Recurrent Neural Networks, October 2023. http://arxiv.org/abs/2311.00159
- Khurana, V., Kumar, Y., et al. Synthesizing Human Gaze Feedback for Improved NLP Performance, May 2023. https://doi.org/10.18653/v1/2023.eacl-main.139
- Hollenstein, N., Barrett, M., et al. Advancing NLP with Cognitive Language Processing Signals, April 2019. http://arxiv.org/abs/1904.02682
- Yang, D., Hollenstein, N. PLM-AS: Pre-trained Language Models Augmented with Scanpaths for Sentiment Classification, January 2023. https://doi.org/10.7557/18.6797
- Kiegeland, S., Reich, D.R., et al. The Pupil Becomes the Master: Eye-Tracking Feedback for Tuning LLMs, July 2024. https://openreview.net/forum?id=8oLUcBgKua
- Deng, S., Prasse, P., et al. Pre-Trained Language Models Augmented with Synthetic Scanpaths for Natural Language Understanding, December 2023. https://doi.org/10.18653/v1/2023.emnlp-main.400
- Mathias, S., Kanojia, D., et al. Eyes are the Windows to the Soul: Predicting the Rating of Text Quality Using Gaze Behaviour, July 2018. https://doi.org/10.18653/v1/P18-1219
- McGuire, E.S., Tomuro, N. Sentiment Analysis with Cognitive Attention Supervision, June 2021. https://doi.org/10.21428/594757db.90170c50
- Zhang, L., Hollenstein, N. Eye-Tracking Features Masking Transformer Attention in Question-Answering Tasks, May 2024. https://aclanthology.org/2024.lrec-main.619